
英文原文:Micro Benchmarking with JMH: Measure, don’t guess!
翻译地址:使用JMH进行微基准测试:不要猜,要测试!
原文作者:Antonio
翻译作者:Hollis
转载请注明出处。
很多Java开发人员都知道把一个变量声明为null有助于垃圾回收(译者注:一般而言,为null的对象都会被作为垃圾处理,所以将不用的对象显式地设为Null,有利于GC收集器判定垃圾,从而提高了GC的效率。),也有部分人知道使用final定义一个内联方法能够提高性能。但是,我们也知道,如今,JVM在不断进化,很多你昨天认定的理论到了今天则不一定试用了。(译者注:因为jvm的不断优化,大多数时候,即时我们不把不用的变量声明为null,垃圾回收器也能很快判断出该对象是否应该被回收。jvm的不断优化之后,把变量设置为null这一举动可能并不会带来显著的性能提升)那么,我们如何能够知道我们写的代码是否高效呢?其实,我们不应该去猜测,而是动手去测试。
Measure, don’t guess!
就像我的朋友 Kirk Pepperdine once said说的那样 “Measure, don’t guess“. 当我们的代码出现性能问题的时候,我们总是试图做一些小的改动(很可能是随意的改动)希望能对性能有所提升。相反,我们应该建立一个稳定的性能测试环境(包括操作系统,jvm,应用服务器,数据库等),设置一些性能目标,针对这一目标不断的进行测试,直到达到你的预期。和持续测试、持续交付类似,我们也应该进行持续的性能测试。
无论如何,性能都是一个黑暗艺术,这不是这篇文章讨论的主要内容。我只是想关注微基准测试和向您展示如何在一个真是的用例(本文以日志记录为例)中使用JMH。
在日志输出中使用微基准测试
相信很多人和我一样,在使用了多个日志框架之后,肯定见过下面这些调试日志:
logger.debug("Concatenating strings " + x + y + z);
logger.debug("Using variable arguments {} {} {}", x, y, z);
if (logger.isDebugEnabled())
logger.debug("Using the if debug enabled {} {} {}", x, y, z);
在一般的应用中,日志输出级别都是INFO或者WARNING。即使使用了WARNING级别,上面这几断代码都可以正常输出调试信息。但是,调试日志可以却可以影响应用的表现(性能)。为了证明这一点,我们将使用微基准测试来测试以上三种代码的性能,这里使用Java微基准测试工具(JMH)。上面的三种代码分别可以概括为:使用字符串连接、使用变量参数和使用If进行debug可用检测。
JMH设置
JMH是一个用于java或者其他JVM语言的,提供构建,运行和分析(按照多种基准:纳秒,微妙、毫秒、宏)的工具。通过maven archtype我们可以很快的创建一个JMH工程。
mvn archetype:generate -DinteractiveMode=false -DarchetypeGroupId=org.openjdk.jmh \
-DarchetypeArtifactId=jmh-java-benchmark-archetype -DarchetypeVersion=1.4.1 \
-DgroupId=org.agoncal.sample.jmh -DartifactId=logging -Dversion=1.0
使用该maven原型创建出来的项目结构如下:
一个包含了JMH相关依赖和maven-shade-plugin插件的pom文件
一个使用了
@Benchmark注解的空的MyBenchmark文件
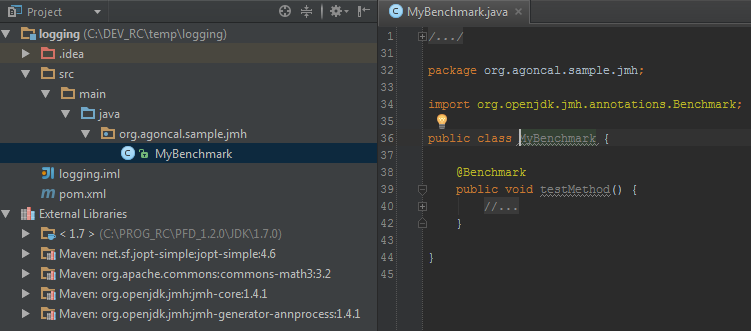
这个时候,虽然我们是什么都还没做,但是我们刚刚创建的微基准测试项目已经可以启动并运行了。使用maven命令打包就能生成一个benchmarks.jar
mvn clean install
java -jar target/benchmarks.jar
当我们使用以上命令运行这个jar时,我们就可以在控制台上看到一些有趣的内容输出:JMH进入循环、预热JVM,执行@Benchmark注解的空方法,并给出每秒操作的数量。
# Run progress: 30,00% complete, ETA 00:04:41
# Fork: 4 of 10
# Warmup Iteration 1: 2207650172,188 ops/s
# Warmup Iteration 2: 2171077515,143 ops/s
# Warmup Iteration 3: 2147266359,269 ops/s
# Warmup Iteration 4: 2193541731,837 ops/s
# Warmup Iteration 5: 2195724915,070 ops/s
# Warmup Iteration 6: 2191867717,675 ops/s
# Warmup Iteration 7: 2143952349,129 ops/s
# Warmup Iteration 8: 2187759638,895 ops/s
# Warmup Iteration 9: 2171283214,772 ops/s
# Warmup Iteration 10: 2194607294,634 ops/s
# Warmup Iteration 11: 2195047447,488 ops/s
# Warmup Iteration 12: 2191714465,557 ops/s
# Warmup Iteration 13: 2229074852,390 ops/s
# Warmup Iteration 14: 2221881356,361 ops/s
# Warmup Iteration 15: 2240789717,480 ops/s
# Warmup Iteration 16: 2236822727,970 ops/s
# Warmup Iteration 17: 2228958137,977 ops/s
# Warmup Iteration 18: 2242267603,165 ops/s
# Warmup Iteration 19: 2216594798,060 ops/s
# Warmup Iteration 20: 2243117972,224 ops/s
Iteration 1: 2201097704,736 ops/s
Iteration 2: 2224068972,437 ops/s
Iteration 3: 2243832903,895 ops/s
Iteration 4: 2246595941,792 ops/s
Iteration 5: 2241703372,299 ops/s
Iteration 6: 2243852186,017 ops/s
Iteration 7: 2221541382,551 ops/s
Iteration 8: 2196835756,509 ops/s
Iteration 9: 2205740069,844 ops/s
Iteration 10: 2207837588,402 ops/s
Iteration 11: 2192906907,559 ops/s
Iteration 12: 2239234959,368 ops/s
Iteration 13: 2198998566,646 ops/s
Iteration 14: 2201966804,597 ops/s
Iteration 15: 2215531292,317 ops/s
Iteration 16: 2155095714,297 ops/s
Iteration 17: 2146037784,423 ops/s
Iteration 18: 2139622262,798 ops/s
Iteration 19: 2213499245,208 ops/s
Iteration 20: 2191108429,343 ops/s
向基准中添加SFL4J
前面不是说过吗,我们要测试的用例是日志记录,那么在这个项目中我将使用SFL4J和Logback,我们向pom文件中增加依赖:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.0.11</version>
</dependency>
然后我们增加一个logback.xml配置文件,并设置日志输出级别为INFO。
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%highlight(%d{HH:mm:ss.SSS} [%thread] %-5level %logger - %msg%n)</pattern>
</encoder>
</appender>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder><pattern>%msg%n</pattern></encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
使用maven-shade-plugin的好处是,当我们使用maven对应用进行打包的时候,所有的依赖和配置文件等都会打包到target目录下。
在日志中使用字符串连接
开始第一个微基准测试:在日志中使用字符串连接。这里我们将所需代码写到由@Benchmark注解标注的方法中,然后其他的事情就交给JMH。
这段代码中,我们创建x,y,z三个字符串变量,然后在循环中,使用字符串连接的形式将调试日志输出。代码如下:
import org.openjdk.jmh.annotations.Benchmark;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MyBenchmark {
private static final Logger logger = LoggerFactory.getLogger(MyBenchmark.class);
@Benchmark
public void testConcatenatingStrings() {
String x = "", y = "", z = "";
for (int i = 0; i < 100; i++) {
x += i; y += i; z += i;
logger.debug("Concatenating strings " + x + y + z);
}
}
}
然后还是像刚刚一样,运行这个微基准测试,并查看迭代输出。
译者注:后文将统一进行对比。
在日志中使用变量参数
这个微基准测试中,我们使用变量参数来代替字符串连接,更改代码内容如下,然后打包执行。
@Benchmark
public void testVariableArguments() {
String x = "", y = "", z = "";
for (int i = 0; i < 100; i++) {
x += i; y += i; z += i;
logger.debug("Variable arguments {} {} {}", x, y, z);
}
}
在日志中使用If判断语句
最后一个也是最重要的一个,使用日志输出时使用isDebugEnabled()进行优化
@Benchmark
public void testIfDebugEnabled() {
String x = "", y = "", z = "";
for (int i = 0; i < 100; i++) {
x += i; y += i; z += i;
if (logger.isDebugEnabled())
logger.debug("If debug enabled {} {} {}", x, y, z);
}
}
微基准测试的结果
在运行三个微基准测试之后,我们将预期结果(记住,don’t guess, measure)。每秒的操作次数越多,表示性能越好。如果我们看看下表的最后一行,我们注意到使用isDebugEnabled的性能最好,使用字符串连接最糟糕。同时也能发现,在没有使用isDebugEnabled而是使用变量参数的测试结果并不差。 综合代码的可读性(较少的boilerplate code(模块化代码,也可以理解为不重要,但是又不可缺少的代码)) 。所以我会选择使用变量参数的那种形式!
| String concatenation | Variable arguments | if isDebugEnabled | |
|---|---|---|---|
| Iteration 1 | 57108,635 ops/s | 97921,939 ops/s | 104993,368 ops/s |
| Iteration 2 | 58441,293 ops/s | 98036,051 ops/s | 104839,216 ops/s |
| Iteration 3 | 58231,243 ops/s | 97457,222 ops/s | 106601,803 ops/s |
| Iteration 4 | 58538,842 ops/s | 100861,562 ops/s | 104643,717 ops/s |
| Iteration 5 | 57297,787 ops/s | 100405,656 ops/s | 104706,503 ops/s |
| Iteration 6 | 57838,298 ops/s | 98912,545 ops/s | 105439,939 ops/s |
| Iteration 7 | 56645,371 ops/s | 100543,188 ops/s | 102893,089 ops/s |
| Iteration 8 | 56569,236 ops/s | 102239,005 ops/s | 104730,682 ops/s |
| Iteration 9 | 57349,754 ops/s | 94482,508 ops/s | 103492,227 ops/s |
| Iteration 10 | 56894,075 ops/s | 101405,938 ops/s | 106790,525 ops/s |
| Average | 57491,4534 ops/s | 99226,5614 ops/s | 104913,1069 ops/s |
## 结论
在过去的几十年jvm大幅进化。用十年前的设计模式优化我们的代码是不可取的。比较两段代码的好坏的唯一办法就是测量它。JMH就是一个简单高效的进行微基准测试的完美工具。当然,推理的一小部分代码只有一个步骤,因为我们通常需要分析整个应用程序的性能。因为有了HMH,让这个第一个步骤变得很容易。
这还有一些JMH的例子,它充满了有趣的想法。





翻译的一个地方有点问题:「即使使用了WARNING级别,上面这几断代码都可以正常输出调试信息。」,这个调试信息明显是不能输出的,不然log级别没用了啊,英文原文是:「But debug logs can have an impact on our performances… even if we are in WARNING level.」意思是:即使log的级别是在WARNING,debug也是会对我们的性能产生很大的影响。