面试官问我平时怎么看源码的,我把这篇文章甩给他了。
本文来自作者投稿,原作者:WwpwW
1.1,为什么要分析源码?
分析源码可以培养一下自己独立思考问题的能力(愿意读源码找问题的能力),最重要的是我们不用再买纸质书去学习数据结构了,数据结构的应用都在源码里面了,正如那句被人熟知的”营养都在汤里面”一样,当我们看过一遍一遍数据结构的理论知识后还是想不起它在哪里用到时,可能看一看源码加上自己的一点思考时就知道它的使用场景了,解答完毕。
1.2,分析源码的好处是?
其实,对于工作一段时间的小伙伴来说,我们都是面向业务开发,就是被人饭后谈资的增删改查程序员/程序猿,当然了,有的人说起来这样的话,”api调包侠”就有点过分了,其实对于我个人来说,我是受不了这样的话语的,因为增删改查是常用的操作,即满足了”二八原则”,其实,程序员/程序猿都是工作中不可或缺的一部分,也是企业开发应用中重要的一环,分析源码可能就会带来显而易见的内功提升,其次就是分析源码的过程中就是在向优秀的人学习的一种体现,毕竟源码里面隐藏了大师多年的心得和思想。
1.3,如何分析源码?
在整个文章的阅读过程中,想必你已经学会了如何分析源码了,从哪入手,这也是一种潜移默化的过程
二, 方法分析
2.1,构造函数
public LinkedBlockingQueue() {
//创建容量为整形最大值
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
//若capacity小于0,则直接抛出参数不合法的异常
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
//默认创建一个元素为null的节点Node
last = head = new Node<E>(null);
}
2.2,add()方法
public boolean add(E e) {
//添加到队列的末尾
addLast(e);
return true;
}
//第二步
public void addLast(E e) {
//若添加失败,则直接抛出队列已满的异常信息,给与提示
if (!offerLast(e))
throw new IllegalStateException("Deque full");
}
//第三步
public boolean offerLast(E e) {
//若添加的元素e为null,则直接抛出空指针异常,因为不允许添加元素为null的情况
if (e == null) throw new NullPointerException();
//构造一个元素为e的节点node
Node<E> node = new Node<E>(e);
final ReentrantLock lock = this.lock;
//进行加锁操作
lock.lock();
try {
//进行第四步操作
return linkLast(node);
} finally {
//进行释放锁,当然了,这里你要记住锁释放是放到finally语句块里面的(重要)
lock.unlock();
}
}
//第四步
private boolean linkLast(Node<E> node) {
// assert lock.isHeldByCurrentThread();
//如果队列里元素个数大于等于了队列的容量,说明此时不能再将元素放入队列里面了,直接返回false即可
if (count >= capacity)
return false;
//创建一个临时变量l,将最后一个节点的引用赋值给l
Node<E> l = last;
//将最后一个节点的引用赋值给新节点node的前一个引用(链表的特点)
node.prev = l;
//将新节点node赋值给最后一个节点(因为元素如队列是放在队列的末尾的,队列的特点->先进先出)
last = node;
//为什么这里要判断first是否为null呢?因为添加时不知道队列里是否已经存在元素,若first为null,说明队列里没有元素
if (first == null)
//此时的node就是第一个结点,赋值即可
first = node;
else
//将新节点node挂在原有结点的下一个,即l.next=node
l.next = node;
//队列元素个数进行加一
++count;
//发送一个信号,队列不满的信号
notEmpty.signal();
//默认将元素e添加到队列里面了~,即返回true
return true;
}
2.3,size()方法
public int size() {
//直接返回队列里表示元素个数的成员变量count即可
return count.get();
}
2.4,peek()方法
public E peek() {
//若队列元素个数为0,说明队列里还未有元素,直接返回null
if (count.get() == 0)
return null;
//获取锁
final ReentrantLock takeLock = this.takeLock;
//进行加锁操作
takeLock.lock();
try {
//获取队列的第一个结点引用first
Node<E> first = head.next;
//若队列的第一个节点引用为null,则直接返回null即可
if (first == null)
return null;
else
//获取第一个节点引用first的元素item返回
return first.item;
} finally {
//进行释放锁,记得释放锁要放在finally语句块里,确保锁可以得到释放
takeLock.unlock();
}
}
2.5,contains()方法
public boolean contains(Object o) {
//引入队列里不允许放入null,所以若元素o为null,则直接返回false,相当于进行了前置校验操作
if (o == null) return false;
//第二步
fullyLock();
try {
//循环遍历队列的每个节点node的元素item是否与元素o相等,若存在相等元素,则包含,返回true即可
for (Node<E> p = head.next; p != null; p = p.next)
if (o.equals(p.item))
return true;
return false;
} finally {
//第四步,第三次说明了,释放锁要放在finally语句块里面,确保锁可以得到正确的释放
fullyUnlock();
}
}
/**
* Locks to prevent both puts and takes.
*/
//第二步,上面的注释说明,进行加锁操作,禁止进行添加元素到队列,禁止进行从队列里取元素,下面就慢慢分析take()方法了
void fullyLock() {
putLock.lock();
takeLock.lock();
}
//第四步,因为加锁和释放锁是成对的,所以最后一定要记得释放锁哈~,即加了什么锁,要对应的解锁
/**
* Unlocks to allow both puts and takes.
*/
void fullyUnlock() {
takeLock.unlock();
putLock.unlock();
}
2.6,put()方法
public void put(E e) throws InterruptedException {
//这个队列是不允许添加空元素的,先来个前置校验,元素为null,则抛出NPE异常
if (e == null) throw new NullPointerException();
// Note: convention in all put/take/etc is to preset local var
// holding count negative to indicate failure unless set.
int c = -1;
//构造一个节点node,元素为e
Node<E> node = new Node<E>(e);
//获取putLock这把锁引用
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
//当队列元素个数等于队列容量capacity时,进行等待,这里存在一个阻塞操作
while (count.get() == capacity) {
notFull.await();
}
//第二步操作,入队列
enqueue(node);
//元素个数增加1,这里使用的是cas机制
c = count.getAndIncrement();
if (c + 1 < capacity)
//进行信号的通知,和notify一样
notFull.signal();
} finally {
//释放锁操作
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
}
//第二步,入队列操作(队列的特点是先进先出)
private void enqueue(Node<E> node) {
//将新元素结点node挂在原有队列最后一个元素的后面,然后将最后一个节点的引用赋值给last
last = last.next = node;
}
2.7,take()方法
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
//获取takeLock锁引用
final ReentrantLock takeLock = this.takeLock;
//这把锁是可以中断的
takeLock.lockInterruptibly();
try {
//若队列元素个数为0,说明队列里没元素了,此时需要进行发送一个等待的通知
while (count.get() == 0) {
notEmpty.await();
}
//进行从队列里进行取元素操作,见下面的第二步操作
x = dequeue();
//队列元素个数进行减一操作
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
// 释放锁
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
//第二步操作
private E dequeue() {
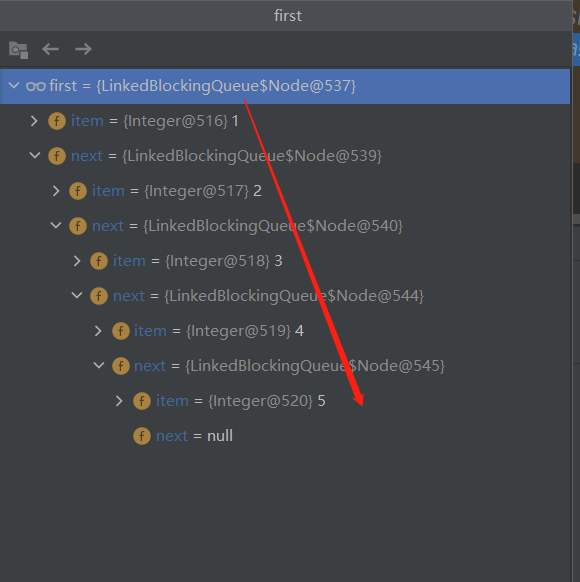
//下面的操作就是队首元素出来了,队列的后面元素要前移,如果这一步不是很好理解的话,可以按照下面的方式进行debug看下
//在分析这块时,自己也有所成长,因为debug是可以看到元素在数据流中如何处理的
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC
head = first;
//获取队首元素x
E x = first.item;
//触发gc机制进行垃圾回收,什么是垃圾对象呢,就是不可达对象,不了解的可以看下jvm对应的机制
first.item = null;
//返回队列的队首元素
return x;
}
2.8,remove()方法
public boolean remove(Object o) {
//这个队列里不允许添加元素为null的元素,所以这里在删除的时候做了一下前置校验
if (o == null) return false;
//第二步,禁止入队列和出队列操作,和上文的contains()方法采取的策略一致
fullyLock();
try {
//循环遍历队列的每个元素,进行比较,这里是不是和你写业务逻辑方法一样,啧啧,有点意思吧
//这里你就明白为什么要看源码了,以及看源码你能得到什么
for (Node<E> trail = head, p = trail.next;
p != null;
trail = p, p = p.next) {
//此时找到待删除的元素o
if (o.equals(p.item)) {
//进行第三步操作
unlink(p, trail);
return true;
}
}
return false;
} finally {
fullyUnlock();
}
}
//第二步,禁止入队列,出队列操作
void fullyLock() {
putLock.lock();
takeLock.lock();
}
//第三步
void unlink(Node<E> p, Node<E> trail) {
//触发gc机制,将垃圾对象进行回收
p.item = null;
//将待删除元素的下一个节点【挂载】待删除元素的前一个元素的next后面
trail.next = p.next;
//判断待删除的元素是否是队列的最后一个元素,如果是,则trail赋值给last,这里你可以想象一下链表的删除操作
if (last == p)
last = trail;
//队列的元素个数减一
if (count.getAndDecrement() == capacity)
notFull.signal();
}
2.9,clear()方法
/**
* Atomically removes all of the elements from this queue.
* The queue will be empty after this call returns.
*/
public void clear() {
//方法上的注释已经说明了clear()方法的作用是干什么的了,很清晰
//在clear()操作时,不允许进行put/take操作,进行了加锁
fullyLock();
try {
//循环遍历队列的每一个元素,将其节点node对应的元素item置为null,触发gc
for (Node<E> p, h = head; (p = h.next) != null; h = p) {
h.next = h;
p.item = null;
}
//队首队尾相同表明队列为空了
head = last;
//将队列的容量capacity置为0
if (count.getAndSet(0) == capacity)
notFull.signal();
} finally {
//记得在这里释放锁
fullyUnlock();
}
}
2.10, toArray()方法
public Object[] toArray() {
//禁止put/take操作,所以进行加锁,看下面的第二步含义
fullyLock();
try {
//获取队列元素个数size
int size = count.get();
//创建大小为size的object数组,之所以为Object类型是因为Object对象的范围最大,什么类型都可以装下
Object[] a = new Object[size];
int k = 0;
//循环遍历队列的每一个元素,将其装入到数组object里面
for (Node<E> p = head.next; p != null; p = p.next)
a[k++] = p.item;
return a;
} finally {
//最后进行释放对应的锁,其实这里你也可以学到很多东西的,比如说加锁,解锁操作,为啥要放到finally语句块呢等等等
//都会潜移默化的指导你编码的过程
fullyUnlock();
}
}
//第二步,注释已经很好的说明了这个方法的含义,就是阻止put和take操作的,所以进行获取对应的锁进行加锁操作
/**
* Locks to prevent both puts and takes.
*/
void fullyLock() {
putLock.lock();
takeLock.lock();
}
2.11,方法总结
这里自己没有对队列的poll()方法,offer()方法进行分析,是因为它和take(),add()方法的分析过程都太一样了,至于一点点差别,你可以去自己看下源码哈,这里由于篇幅的问题就不过多介绍了,其实整个方法的分析就是基于链表和数组的操作。不过这里没有在方法的分析过程中去写时间复杂度,不过,你看过vector源码之后就知道如何分析了。
三,总结一下
3.1,思考一下
文章的开头抛出了下面的3个问题
1.1,为什么要分析源码? 那我这里在问下,你分析完这个集合源码,学习到了什么?是不是有点启发?
1.2,分析源码的好处是? 在分析的过程中,你学会了如何更加去编码,或许你没有意识到,但这是潜移默化的过程,相信你学习到了
1.3,如何分析源码? 在整个文章的阅读过程中,想必你已经学会了如何分析源码了,从哪入手,这也是一种潜移默化的过程